Update: A challenger appears. My security researcher friend Fox has challenged me to a duel. See her blog post for the details.
This is part of the Reflection series in which I go through my old projects and tell their story.
CAPTCHAs have become an integral part of the web in the last few years. Almost everyone on the web has encountered those twisted pictures, probably when signing up to an email service. They come in various shapes, sizes, colors and cats. When they first became popular, there was an explosion of different types of schemes that services used (who can forget Rapidshare’s cat captcha?).
Now as with every security measure there is a compromise between usability and protection. Some of the easier CAPTCHAs were broken using only OCR software, while some of the latest reCAPTCHA images are hard even for a human to solve (interesting but out dated chart).
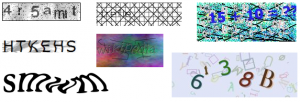
One such service was UrlShield. You would give UrlShield a URL you want to protect from bots and it created a page with a CAPTCHA that when solved correctly redirected you to your original URL. Simple enough. I can certainly see a use for such a service, for example if you want to give out promotional coupons and don’t want bots to snatch all of them. The service became popular in some file sharing sites for the same exact reason.
The particular image this site was generating had a checkerboard background with 4 characters all in different colors, sometimes overlapping. It was pretty easy for a human to parse it.
It even works pretty good against OCR. I used Microsoft OneNote OCR feature which uses the commercial OmniPage software to create the second column.
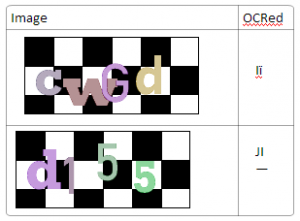
So far so good? Well, no. This scheme is flawed because it is easy to transform the image – remove the background and segment it (split it to region that each contains a single character), allowing OCR tools to easily get the letter. To remove the background you just clear all the black pixels out of the image. To segment it all you need to do is choose one color and mask all the others, which means you’ll end up with a single letter, as each letter is in a different color. This is what you end up with:

OneNote has no problem parsing each of these to a letter.
The process described above is exactly what UnUrlShield does. It’s a simple Python script that use the Python Imaging Library to read the image. Then it counts all the colors that appear more than a certain threshold (MIN_PIXEL_PER_LETTER_COUNT) and saves each color’s pixel location. Lastly it goes through the colors, creating an image with only that color’s pixel locations.
Is there a lesson here about CAPTCHAs? I think so. UrlShield is now some kind of ad/malware site. Even complicated CAPTCHAs can be broken, or even better – be defeated by side-channel attacks like having an army of low-cost workers break them on-demand (The comments of this article are a treasure trove of irony) and sometimes people are even fooled into breaking CAPTCHAs. This is why it amazes me they are still around, annoying normal regular people while also being broken by even slightly motivated attackers.
Are there no solutions to spam? Of course there are! In fact gmail does a great job at stopping 100% of my spam using things like blacklisting known spammers, Bayesian filtering, “crowd-sourcing” protection (the “mark as spam” button) and other tools that don’t rely on CAPTCHAs.
Do you have good examples of silly, easily broken or bizzare CAPTCHAs? Did you find an easy way around some services blocked by CAPTCHAs? Leave a comment below and tell me about it!
For wordpress blogs, Akismet does a very good job in blocking SPAM based on crowdsourcing and some AI. While it still lets through about 1% of the SPAM, you don’t annoy legitimate users with Captchas. I am wondering whether there is a reliable solution for filtering the remaining 1% of the SPAM for human inspection…
To be honest, if spam becomes an issue on this blog I know I’m doing at least something right 🙂
I wish this was an indicator, but automated scripts
do not care if you are doing right or not. As long as
your page is indexed in google in some way, they
will eventually get to it and start bombing it, you will
get it regardless of PR or whatever…
p.s. did you manage to make email notifications
work?
I’m not afraid of SPAM, and I’m sure there are enough server-side ways I can prevent them without adding CAPTCHAs to the comments section.
Email notification should work as far as I can tell.
Congratz, it is working!
There is another conceptual approach to the issue of spam that might be a bit easier on users- instead of providing a challenge in the form of something a human would know that a bot doesn’t know, one could provide a challenge that is something a bot doesn’t know that it’s not SUPPOSED to know.
For example, plays on visibility: When filling a form, e.g. submitting a comment (which is where one might expect a spam bot to try and squeeze itself in), having fields that are visually hidden from a human but are coded into the page as part of the form- the bot would likely fill it (because its logic attempts to fill in any field with a name/id that looks familiar and/or generally any field where free text is allowed) whereas in a submission made by a human, the field would remain empty, thus exposing the spam bot.
This, of course, has issues of its own (such as browsers auto-fill making similar mistakes to the bots, etc.), but I’ve seen it around a bit and I’m sure it can be polished into a decent anti-spam mechanism.
What is stopping the bots from only filling up visible form fields? It’s not trivial but it is certainly possible to find out what fields should be visible. The thing is – human input should never be trusted, even when it comes from bots :). Every client-side measure is bound to fail.
What’s stopping them from only filling in visible fields? Much like with many other things- the fact that they don’t. For now. There are also many ways to make something “not visible” to a user- for a spam bot to parse a page to the point of understanding layout and knowing what’s going to be on and off the page it’s a lot of work, the cost-effectiveness goes down by a lot, which makes them think twice before attempting to implement it.
There are a lot of ways to visually hide things in a page, it’s not just setting visibility to ‘hidden’, CSS is a horrifyingly wonderful (or wonderfully horrifying?) technology for just such purposes…
Well the easiest way I can think about is just compiling webkit into your code and letting it do the heavy work of finding hidden stuff. Actually I might even go as far as saying that if your site works on firefox a smart enough bot will never be fooled by that trick.
Your point is still valid though, bots are not smart enough yet, so that trick might work for now.
Ohhh, I DARE you to write something that finds “hidden stuff” in a page using whatever webkit you bloody wish… Easier said than done, if you ask me. :>
Dare accepted. Also notice this reply should also be emailed to you 🙂
Have fun @ black hat 🙂